
Back in high school, when I was 16 years old, I developed Megamax, a chess engine written entirely in Python. I wanted to combine my two biggest passions at the time, coding and playing chess, into one project. That's how Megamax was born.

Training a computer to play chess is like teaching a baby. At first, it doesn't know anything about the pieces, how they move, or what can and can't be done. And let's not even talk about en passant!
Hard-coding all of this into a script could take a long time and, luckily for me, I found a Python library called python-chess that already had a nice board representation and a legal-move generator.
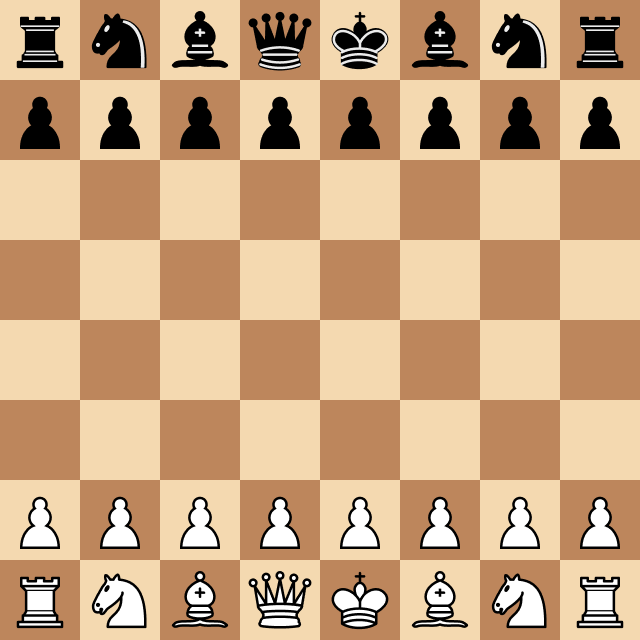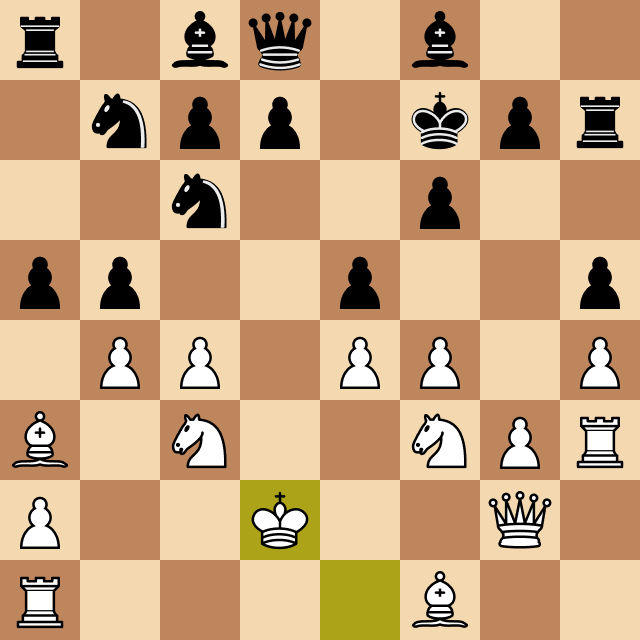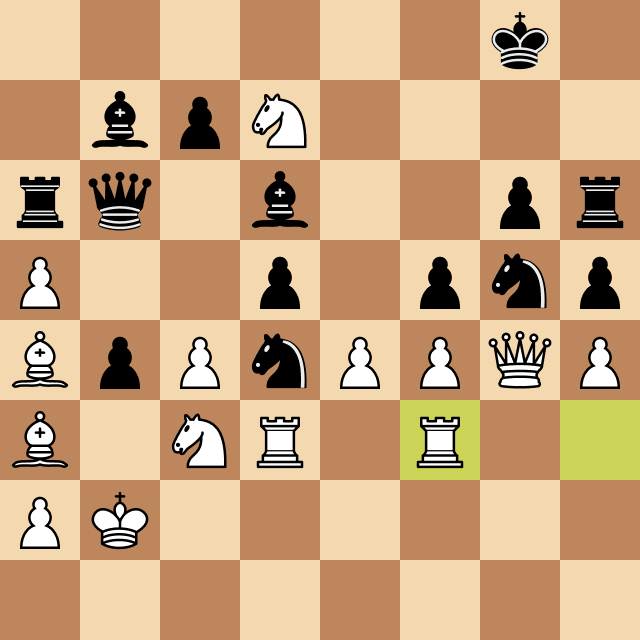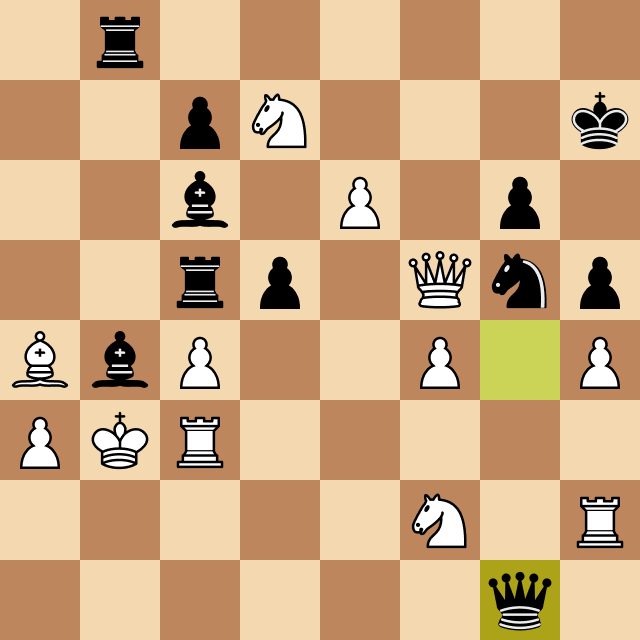
Using that library, it was easy to get all the legal moves from a given board position and thus make a correct move. But here, by "correct," I mean legal. The results of playing randomly are, as expected, really, really bad. Take a look:
The algorithm that powers Megamax is called Minimax. It's a kind of deep search through the move tree to find the best move in each case. Unlike simple games like tic-tac-toe, in chess the tree formed by all possible moves from the starting position is enormous (some say it contains more possibilities than the number of atoms in the entire universe), so it's completely unrealistic to represent the whole chess game tree.
The more moves we look ahead, though, the better moves we may find, but the harder it will be for the program to compute all the moves, and as a result, the search will take longer.
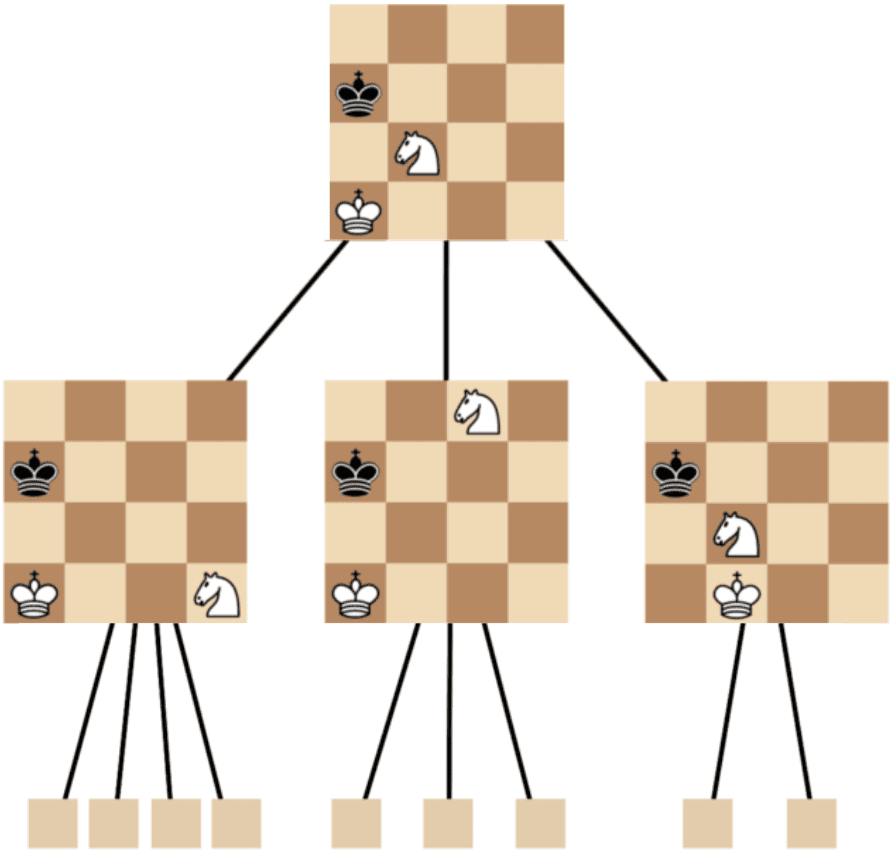
At first, I settled on depth level 3 and tried it out. It took approximately 35 seconds for the program to look through the possible moves and compute the best one at this depth level. That's too slow for me, even for a slow language like Python! (More on that later.)
To improve this time, I implemented the Alpha-Beta optimization. Like a farmer pruning a field, this algorithm cuts branches of the move tree that are proven to be worse than others. You can read more about this algorithm here.
After applying this optimization and sorting the moves to prioritize captures, pawn promotions, and check opportunities, my program's response time at depth 3 decreased to 4-10 seconds, which is much more acceptable for normal timed games.
When testing this version against myself (a normal chess player) I noticed it made a terrible blunder that I couldn't explain at first. Take a look:
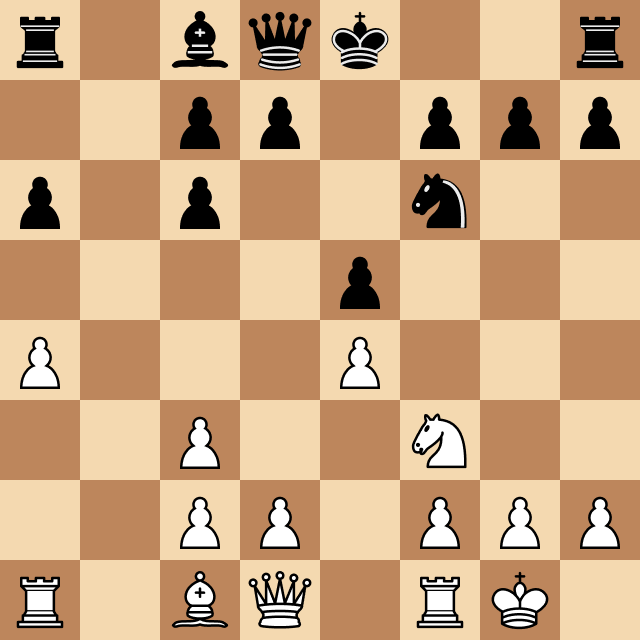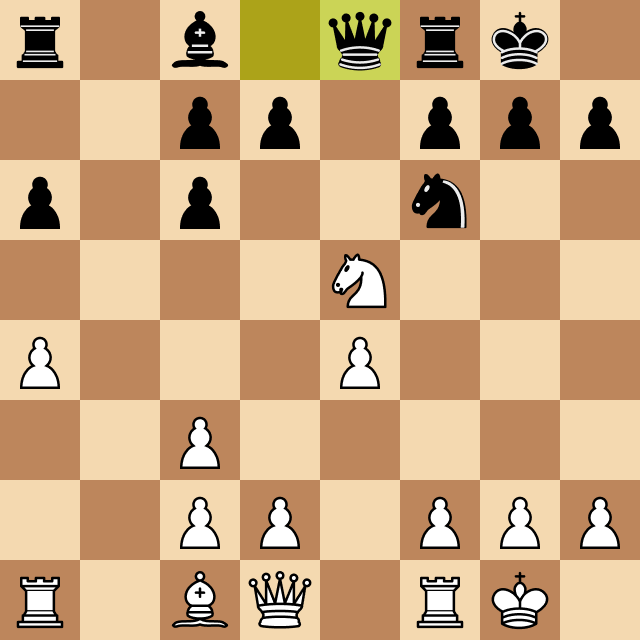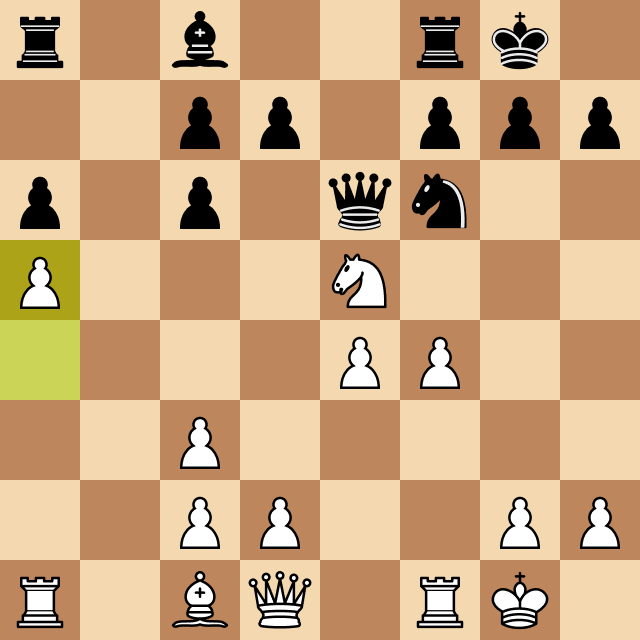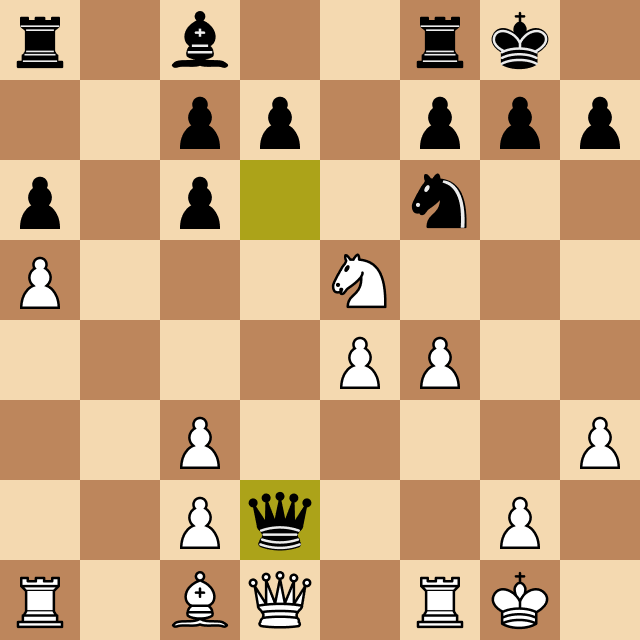
The Horizon Effect
The cause of the program's mistake has a name: it's called the horizon effect, and it's caused by the strict depth limit that I had imposed on the program at the time.
Megamax was only calculating the best move up to that depth, and in the previous case, since it was the queen capturing a pawn, it thought that was a good option. It didn't look at the next possible moves, so it didn't realize that the hungry rook would capture the queen.

Luckily, there's also a solution to this phenomenon, and it's relatively straightforward. If the last checked move is a capture, we have to force the program to check one depth level deeper. That made the program much better at playing against me.
Opening books & Endgame tablebase
Playing against the program, I realized that Megamax always started with the same opening move. That's bad because it means the engine is predictable, which makes it easier to beat.
To solve this, I incorporated opening books (a collection of common opening moves that the program can use during the opening phase). This teaches the program many options to begin with and common patterns to follow, putting it in a good position to play the game.
After implementing that, I started testing the program against other chess engines that could be set to play at specific ELO ratings. During one of these games, I encountered a common scenario: it seemed that Megamax was unable to win, even when it had enough pieces and positional advantage to deliver checkmate.
Take a look below. Why was that?
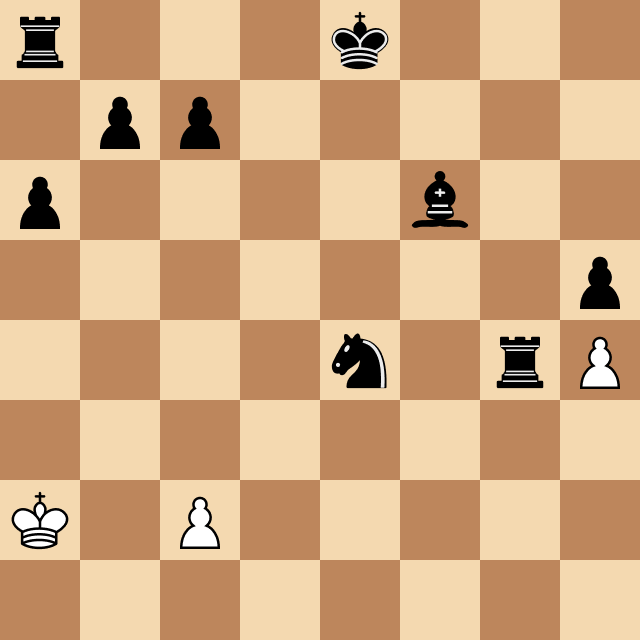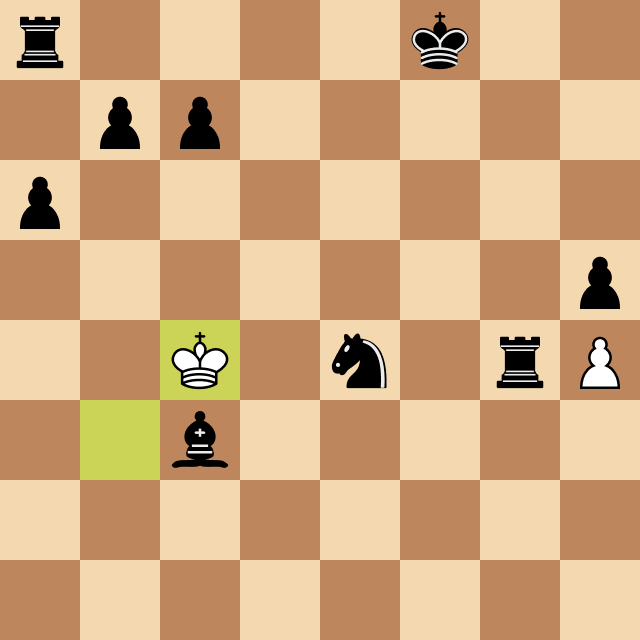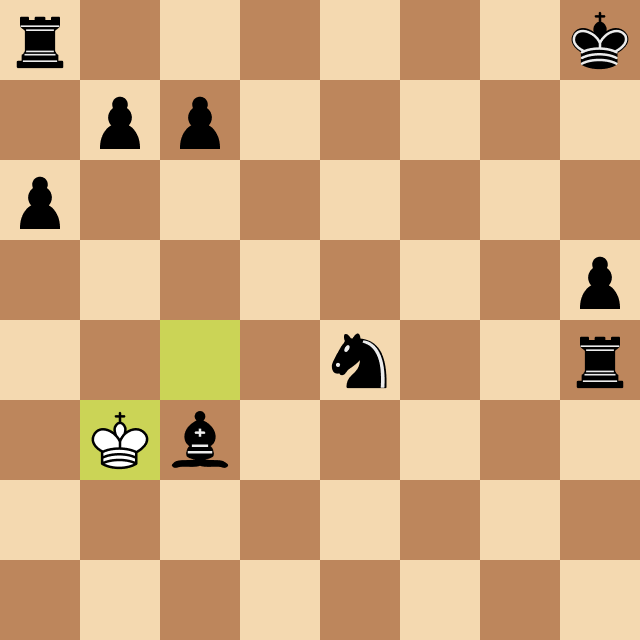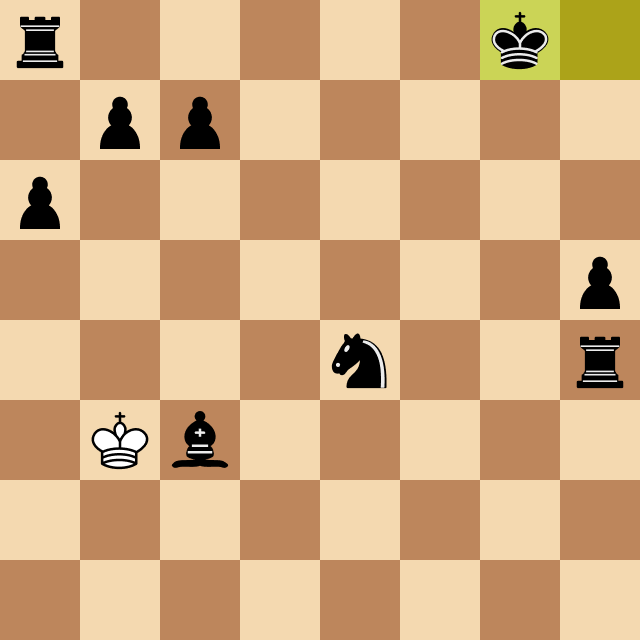
The reason for this behavior is that in some cases, it takes many moves to perform checkmate, and if that number is greater than the program's search depth, it won't be able to execute it. The solution? Endgame tablebase. They work just like opening books but cover common checkmate positions with up to 7 pieces on the board.
After adding this system, Megamax was able to play full-length games and beat chess players up to 1600 ELO rating, as can be seen below, against a 1600 ELO chess engine. After evaluating the program, we estimated its ELO level at around 1600.
The final game
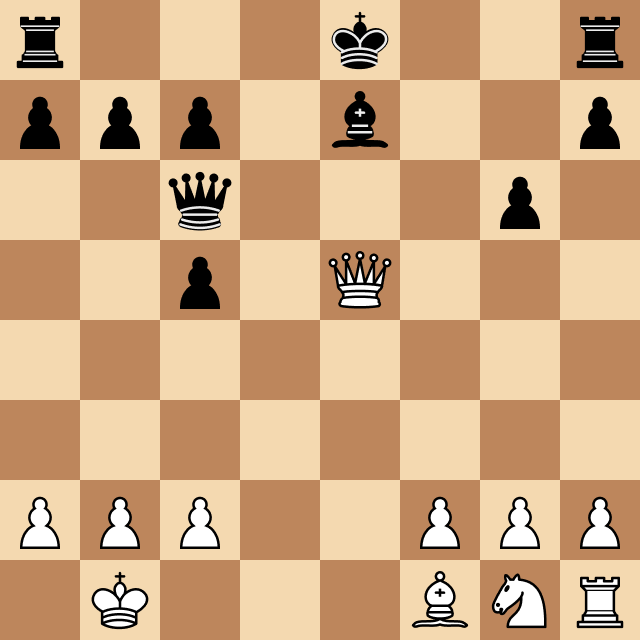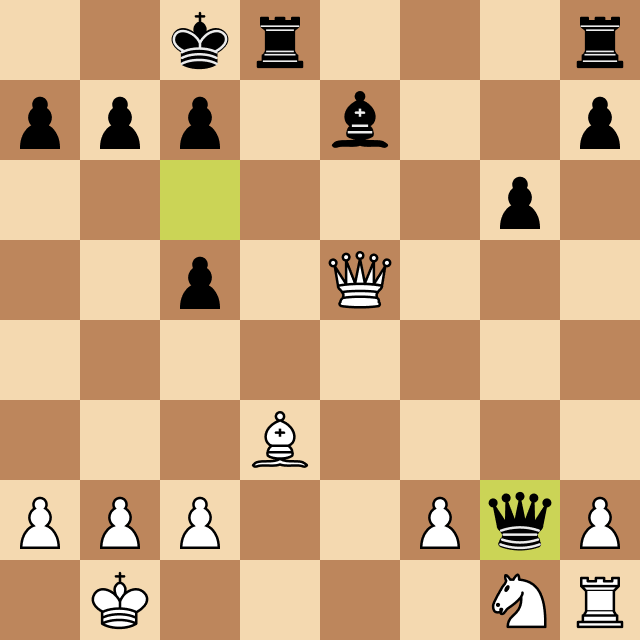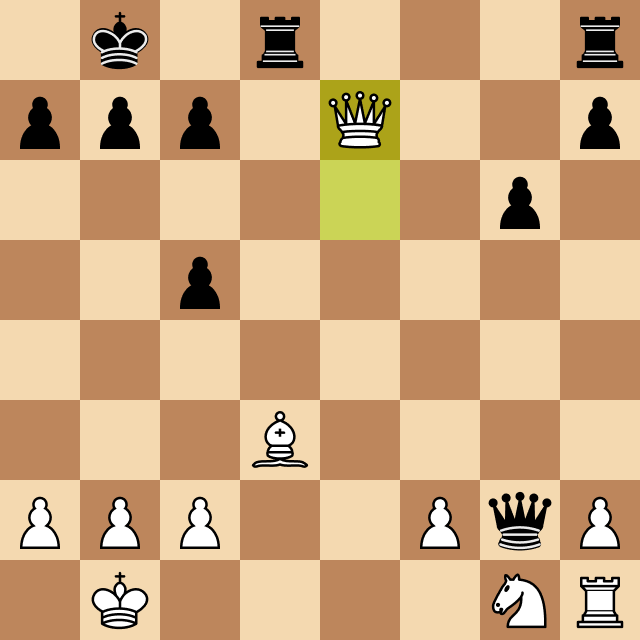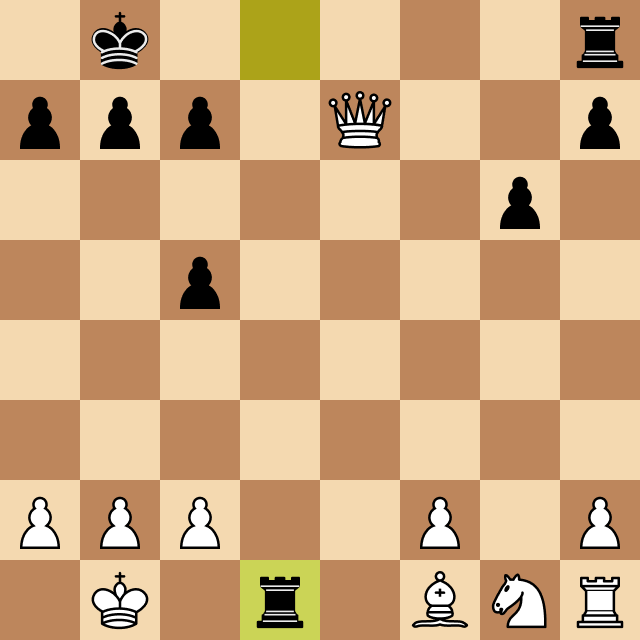
When Josep Oms Pallise, one of Spain's top chess players (a chess grandmaster with a nearly 2500 ELO rating), heard about the project, he agreed to play against Megamax.
Of course, the rating difference between the program and Oms was very significant, and we were running the engine on a standard Windows computer, so the odds were really bad for Megamax.

The resulting game, however, was fascinating, and Josep's comments as he played provided amazing insight into the chess world and the human thinking strategies that led him to beat Megamax, running at depth 4. Take a look at the moment when Oms beats Megamax and ends the game.
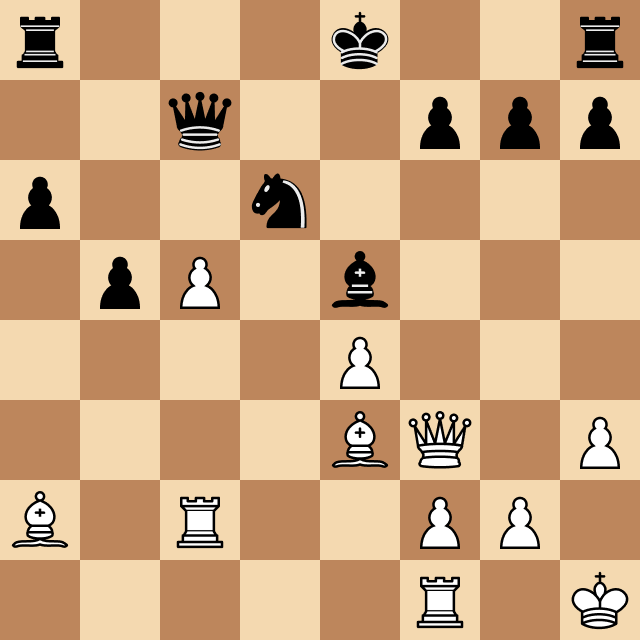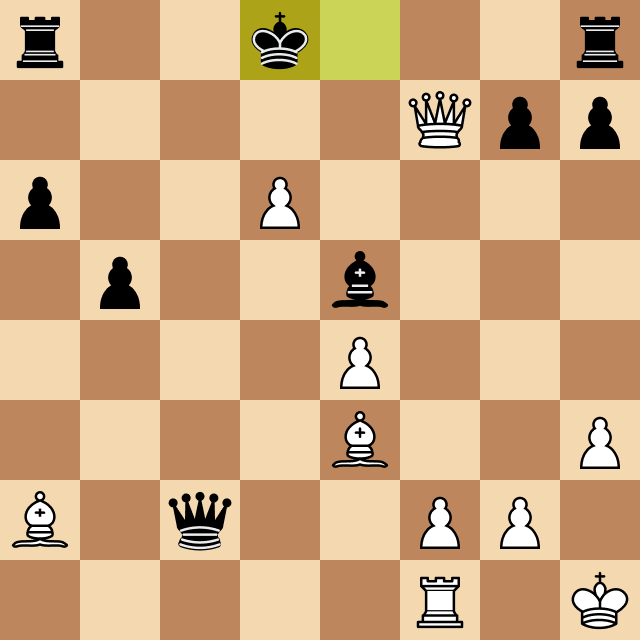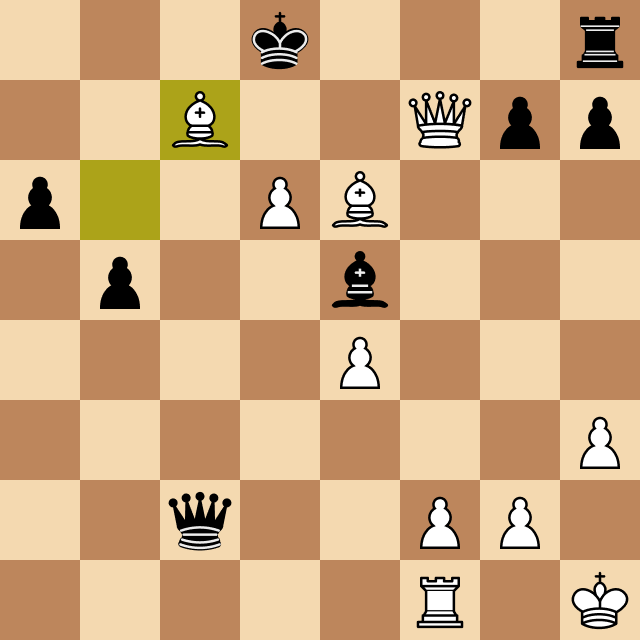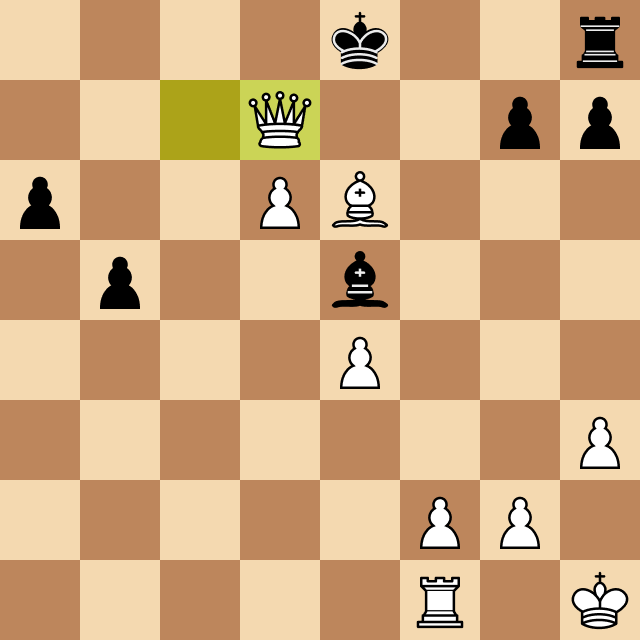
What I Learned
Building Megamax was an amazing experience back then, and I still have very fond memories of the hours I spent coding and playing against my engine.
One big lesson I learned from this project is that python is a really slow programming language. It's approximately 100 times slower than C++, and that difference makes it a poor choice for building computationally intensive programs like this.
I want to thank my tutor, Marc Llovera, who pushed me forward and held me back when I was thinking about rewriting the entire codebase in C++ the weekend before the match against Josep Oms.
I also had the honor of presenting Megamax alongside him at Mobile Week La Seu back in 2022. You can watch the talk we gave here.

The story also appeared in the press at the time. One of the articles about the project was published by TV3's 324 and can be found here.

